

Write The Complementary Dna Strand
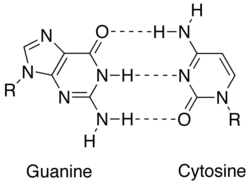
Match upwardly between 2 Dna bases (guanine and cytosine) showing hydrogen bonds (dashed lines) holding them together

Match up between two Deoxyribonucleic acid bases (adenine and thymine) showing hydrogen bonds (dashed lines) holding them together
In molecular biology, complementarity describes a relationship between 2 structures each post-obit the lock-and-key principle. In nature complementarity is the base principle of Dna replication and transcription as it is a belongings shared between 2 DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences volition be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base of operations pairing allows cells to copy data from ane generation to another and even find and repair damage to the data stored in the sequences.
The degree of complementarity between two nucleic acid strands may vary, from complete complementarity (each nucleotide is across from its opposite) to no complementarity (each nucleotide is non beyond from its contrary) and determines the stability of the sequences to exist together. Furthermore, various DNA repair functions besides as regulatory functions are based on base of operations pair complementarity. In biotechnology, the principle of base pair complementarity allows the generation of DNA hybrids between RNA and DNA, and opens the door to modern tools such as cDNA libraries. While most complementarity is seen betwixt two separate strings of DNA or RNA, it is as well possible for a sequence to have internal complementarity resulting in the sequence binding to itself in a folded configuration.
Deoxyribonucleic acid and RNA base pair complementarity [edit]

Complementarity betwixt 2 antiparallel strands of DNA. The pinnacle strand goes from the left to the correct and the lower strand goes from the right to the left lining them up.

Left: the nucleotide base of operations pairs that can form in double-stranded Deoxyribonucleic acid. Between A and T there are two hydrogen bonds, while there are three between C and K. Right: two complementary strands of Dna.
Complementarity is achieved by distinct interactions between nucleobases: adenine, thymine (uracil in RNA), guanine and cytosine. Adenine and guanine are purines, while thymine, cytosine and uracil are pyrimidines. Purines are larger than pyrimidines. Both types of molecules complement each other and can simply base pair with the opposing type of nucleobase. In nucleic acid, nucleobases are held together past hydrogen bonding, which merely works efficiently between adenine and thymine and betwixt guanine and cytosine. The base complement A = T shares two hydrogen bonds, while the base pair G ≡ C has three hydrogen bonds. All other configurations between nucleobases would hinder double helix germination. Deoxyribonucleic acid strands are oriented in reverse directions, they are said to exist antiparallel.[1]
| Nucleic Acid | Nucleobases | Base complement |
| DNA | adenine(A), thymine(T), guanine(G), cytosine(C) | A = T, K ≡ C |
| RNA | adenine(A), uracil(U), guanine(G), cytosine(C) | A = U, Thou ≡ C |
A complementary strand of DNA or RNA may exist constructed based on nucleobase complementarity.[ii] Each base pair, A = T vs. Chiliad ≡ C, takes up roughly the same infinite, thereby enabling a twisted Deoxyribonucleic acid double helix formation without whatever spatial distortions. Hydrogen bonding between the nucleobases too stabilizes the DNA double helix.[three]
Complementarity of Dna strands in a double helix brand it possible to use 1 strand as a template to construct the other. This principle plays an important office in DNA replication, setting the foundation of heredity past explaining how genetic information can be passed down to the next generation. Complementarity is also utilized in DNA transcription, which generates an RNA strand from a DNA template.[iv] In addition, man immunodeficiency virus, a single-stranded RNA virus, encodes an RNA-dependent Deoxyribonucleic acid polymerase (opposite transcriptase) that uses complementarity to catalyze genome replication. The reverse transcriptase can switch betwixt 2 parental RNA genomes by copy-choice recombination during replication.[v]
DNA repair mechanisms such as proof reading are complementarity based and allow for error correction during DNA replication past removing mismatched nucleobases.[i] In general, damages in one strand of DNA can be repaired by removal of the damaged section and its replacement past using complementarity to copy information from the other strand, as occurs in the processes of mismatch repair, nucleotide excision repair and base excision repair.[6]
Nucleic acids strands may too form hybrids in which single stranded DNA may readily anneal with complementary Deoxyribonucleic acid or RNA. This principle is the basis of commonly performed laboratory technique such as the polymerase chain reaction, PCR.[one]
Two strands of complementary sequence are referred to every bit sense and anti-sense. The sense strand is, generally, the transcribed sequence of Dna or the RNA that was generated in transcription, while the anti-sense strand is the strand that is complementary to the sense sequence.
Self-complementarity and hairpin loops [edit]

A sequence of RNA that has internal complementarity which results in it folding into a hairpin
Self-complementarity refers to the fact that a sequence of Deoxyribonucleic acid or RNA may fold back on itself, creating a double-strand similar structure. Depending on how shut together the parts of the sequence are that are cocky-complementary, the strand may grade hairpin loops, junctions, bulges or internal loops.[one] RNA is more likely to course these kinds of structures due to base pair binding non seen in DNA, such as guanine binding with uracil.[one]

A sequence of RNA showing hairpins (far right and far upper left), and internal loops (lower left construction)
Regulatory functions [edit]
Complementarity can be constitute between short nucleic acid stretches and a coding region or an transcribed gene, and results in base pairing. These short nucleic acid sequences are usually constitute in nature and have regulatory functions such as gene silencing.[one]
Antisense transcripts [edit]
Antisense transcripts are stretches of non coding mRNA that are complementary to the coding sequence.[seven] Genome wide studies have shown that RNA antisense transcripts occur commonly within nature. They are mostly believed to increase the coding potential of the genetic code and add an overall layer of complexity to gene regulation. So far, it is known that forty% of the man genome is transcribed in both directions, underlining the potential significance of reverse transcription.[8] It has been suggested that complementary regions between sense and antisense transcripts would permit generation of double stranded RNA hybrids, which may play an important role in gene regulation. For example, hypoxia-induced factor 1α mRNA and β-secretase mRNA are transcribed bidirectionally, and information technology has been shown that the antisense transcript acts every bit a stabilizer to the sense script.[9]
miRNAs and siRNAs [edit]

Formation and function of miRNAs in a prison cell
miRNAs, microRNA, are short RNA sequences that are complementary to regions of a transcribed gene and have regulatory functions. Electric current research indicates that circulating miRNA may be utilized as novel biomarkers, hence show promising evidence to be utilized in disease diagnostics ..[ten] MiRNAs are formed from longer sequences of RNA that are cut free past a Dicer enzyme from an RNA sequence that is from a regulator factor. These brusk strands bind to a RISC circuitous. They lucifer up with sequences in the upstream region of a transcribed factor due to their complementarity to act as a silencer for the gene in iii means. One is past preventing a ribosome from binding and initiating translation. Two is by degrading the mRNA that the complex has bound to. And three is by providing a new double-stranded RNA (dsRNA) sequence that Dicer tin act upon to create more miRNA to find and degrade more than copies of the gene. Small interfering RNAs (siRNAs) are similar in function to miRNAs; they come up from other sources of RNA, but serve a similar purpose to miRNAs.[1] Given their short length, the rules for complementarity means that they can still be very discriminating in their targets of pick. Given that there are 4 choices for each base in the strand and a 20bp - 22bp length for a mi/siRNA, that leads to more than than 1×1012 possible combinations. Given that the human genome is ~3.1 billion bases in length,[11] this means that each miRNA should only find a friction match once in the unabridged human being genome past blow.
Kissing hairpins [edit]
Kissing hairpins are formed when a single strand of nucleic acrid complements with itself creating loops of RNA in the form of a hairpin.[12] When 2 hairpins come into contact with each other in vivo, the complementary bases of the two strands form upward and begin to unwind the hairpins until a double-stranded RNA (dsRNA) circuitous is formed or the complex unwinds back to two separate strands due to mismatches in the hairpins. The secondary structure of the hairpin prior to kissing allows for a stable structure with a relatively fixed change in free energy.[13] The purpose of these structures is a balancing of stability of the hairpin loop vs bounden forcefulness with a complementary strand. Too potent an initial binding to a bad location and the strands will non unwind quickly plenty; besides weak an initial binding and the strands volition never fully form the desired complex. These hairpin structures let for the exposure of enough bases to provide a strong plenty bank check on the initial bounden and a weak enough internal binding to permit the unfolding once a favorable match has been found.[13]
---C Thousand--- C One thousand ---C G--- U A C G G C U A C G 1000 C A Thou C Yard A A A G C U A A U CUU ---CCUGCAACUUAGGCAGG--- A GAA ---GGACGUUGAAUCCGUCC--- M A U U U U U C U C G C Grand C C G C G A U A U 1000 C One thousand C ---Thousand C--- ---G C--- Kissing hairpins meeting up at the top of the loops. The complementarity of the two heads encourages the hairpin to unfold and straighten out to become 1 flat sequence of 2 strands rather than two hairpins.
Bioinformatics [edit]
Complementarity allows information found in Dna or RNA to be stored in a single strand. The complementing strand can be adamant from the template and vice versa as in cDNA libraries. This also allows for assay, like comparing the sequences of two different species. Shorthands have been developed for writing down sequences when there are mismatches (ambiguity codes) or to speed upwards how to read the opposite sequence in the complement (ambigrams).
cDNA Library [edit]
A cDNA library is a drove of expressed Dna genes that are seen as a useful reference tool in gene identification and cloning processes. cDNA libraries are constructed from mRNA using RNA-dependent DNA polymerase opposite transcriptase (RT), which transcribes an mRNA template into Deoxyribonucleic acid. Therefore, a cDNA library tin only contain inserts that are meant to be transcribed into mRNA. This process relies on the principle of DNA/RNA complementarity. The finish product of the libraries is double stranded Dna, which may exist inserted into plasmids. Hence, cDNA libraries are a powerful tool in modernistic research.[1] [xiv]
Ambiguity codes [edit]
When writing sequences for systematic biology it may be necessary to have IUPAC codes that hateful "any of the two" or "whatever of the three". The IUPAC lawmaking R (whatsoever purine) is complementary to Y (any pyrimidine) and Thousand (amino) to One thousand (keto). W (weak) and S (strong) are usually not swapped[15] but have been swapped in the past by some tools.[xvi] W and S denote "weak" and "strong", respectively, and indicate a number of the hydrogen bonds that a nucleotide uses to pair with its complementing partner. A partner uses the same number of the bonds to make a complementing pair.[17]
An IUPAC code that specifically excludes 1 of the three nucleotides can be complementary to an IUPAC code that excludes the complementary nucleotide. For instance, V (A, C or Thousand - "not T") tin can be complementary to B (C, Chiliad or T - "non A").
| Symbol[18] | Description | Bases represented | ||||
|---|---|---|---|---|---|---|
| A | adenine | A | 1 | |||
| C | cytosine | C | ||||
| K | thousanduanine | G | ||||
| T | thymine | T | ||||
| U | uracil | U | ||||
| W | westeak | A | T | 2 | ||
| S | strong | C | Thou | |||
| K | athouino | A | C | |||
| K | keto | Thou | T | |||
| R | purine | A | G | |||
| Y | pyrimidine | C | T | |||
| B | non A (B comes after A) | C | M | T | 3 | |
| D | not C (D comes afterward C) | A | Grand | T | ||
| H | not G (H comes afterwards G) | A | C | T | ||
| V | not T (V comes after T and U) | A | C | G | ||
| Northward or - | any base (not a gap) | A | C | One thousand | T | four |
Ambigrams [edit]
Specific characters may be used to create a suitable (ambigraphic) nucleic acrid notation for complementary bases (i.due east. guanine = b, cytosine = q, adenine = north, and thymine = u), which makes it is possible to complement entire Dna sequences by simply rotating the text "upside down".[19] For instance, with the previous alphabet, buqn (GTCA) would read every bit ubnq (TGAC, reverse complement) if turned upside down.
- qqubqnnquunbbqnbb
- bbnqbuubnnuqqbuqq
Ambigraphic notations readily visualize complementary nucleic acid stretches such as palindromic sequences.[xx] This feature is enhanced when utilizing custom fonts or symbols rather than ordinary ASCII or even Unicode characters.[xx]
See besides [edit]
- Base of operations pair
References [edit]
- ^ a b c d e f g h Watson, James, Cold Bound Harbor Laboratory, Tania A. Bakery, Massachusetts Institute of Technology, Stephen P. Bell, Massachusetts Institute of Applied science, Alexander Gann, Cold Spring Harbor Laboratory, Michael Levine, Academy of California, Berkeley, Richard Losik, Harvard University ; with Stephen C. Harrison, Harvard Medical (2014). Molecular biology of the gene (Seventh ed.). Boston: Benjamin-Cummings Publishing Company. ISBN978-0-32176243-6.
- ^ Pray, Leslie (2008). "Discovery of Deoxyribonucleic acid construction and function: Watson and Crick". Nature Didactics. 1 (i): 100. Retrieved 27 November 2013.
- ^ Shankar, A; Jagota, A; Mittal, J (Oct eleven, 2012). "DNA base of operations dimers are stabilized by hydrogen-bonding interactions including not-Watson-Crick pairing near graphite surfaces". The Journal of Physical Chemistry B. 116 (40): 12088–94. doi:10.1021/jp304260t. PMID 22967176.
- ^ Hood, L; Galas, D (January 23, 2003). "The digital lawmaking of Deoxyribonucleic acid". Nature. 421 (6921): 444–eight. Bibcode:2003Natur.421..444H. doi:ten.1038/nature01410. PMID 12540920.
- ^ Rawson JMO, Nikolaitchik OA, Keele BF, Pathak VK, Hu WS. Recombination is required for efficient HIV-ane replication and the maintenance of viral genome integrity. Nucleic Acids Res. 2018;46(20):10535-10545. DOI:x.1093/nar/gky910 PMID 30307534
- ^ Chip O, Nielsen O. DNA repair. J Prison cell Sci. 2004;117(Pt four):515-517. DOI:10.1242/jcs.00952
- ^ He, Y; Vogelstein, B; Velculescu, VE; Papadopoulos, N; Kinzler, KW (Dec xix, 2008). "The antisense transcriptomes of man cells". Science. 322 (5909): 1855–vii. Bibcode:2008Sci...322.1855H. doi:10.1126/scientific discipline.1163853. PMC2824178. PMID 19056939.
- ^ Katayama, S; Tomaru, Y; Kasukawa, T; Waki, K; Nakanishi, M; Nakamura, M; Nishida, H; Yap, CC; Suzuki, G; Kawai, J; Suzuki, H; Carninci, P; Hayashizaki, Y; Wells, C; Frith, M; Ravasi, T; Pang, KC; Hallinan, J; Mattick, J; Hume, DA; Lipovich, L; Batalov, S; Engström, PG; Mizuno, Y; Faghihi, MA; Sandelin, A; Chalk, AM; Mottagui-Tabar, S; Liang, Z; Lenhard, B; Wahlestedt, C; RIKEN Genome Exploration Enquiry Group; Genome Science Group (Genome Network Project Core Group); FANTOM Consortium (Sep 2, 2005). "Antisense transcription in the mammalian transcriptome". Science. 309 (5740): 1564–6. Bibcode:2005Sci...309.1564R. doi:10.1126/science.1112009. PMID 16141073. S2CID 34559885.
- ^ Faghihi, MA; Zhang, M; Huang, J; Modarresi, F; Van der Brug, MP; Nalls, MA; Cookson, MR; St-Laurent G, tertiary; Wahlestedt, C (2010). "Evidence for natural antisense transcript-mediated inhibition of microRNA part". Genome Biology. 11 (5): R56. doi:10.1186/gb-2010-eleven-5-r56. PMC2898074. PMID 20507594.
- ^ Kosaka, N; Yoshioka, Y; Hagiwara, Grand; Tominaga, N; Katsuda, T; Ochiya, T (Sep five, 2013). "Trash or Treasure: extracellular microRNAs and jail cell-to-jail cell communication". Frontiers in Genetics. 4: 173. doi:ten.3389/fgene.2013.00173. PMC3763217. PMID 24046777.
- ^ "Ensembl genome browser 73: Homo sapiens - Assembly and Genebuild". Ensembl.org . Retrieved 27 November 2013.
- ^ Marino, JP; Gregorian RS, Jr; Csankovszki, One thousand; Crothers, DM (Jun 9, 1995). "Bent helix formation between RNA hairpins with complementary loops". Scientific discipline. 268 (5216): 1448–54. Bibcode:1995Sci...268.1448M. doi:10.1126/science.7539549. PMID 7539549.
- ^ a b Chang, KY; Tinoco I, Jr (May xxx, 1997). "The structure of an RNA "kissing" hairpin complex of the HIV TAR hairpin loop and its complement". Journal of Molecular Biology. 269 (ane): 52–66. doi:10.1006/jmbi.1997.1021. PMID 9193000.
- ^ Wan, KH; Yu, C; George, RA; Carlson, JW; Hoskins, RA; Svirskas, R; Stapleton, M; Celniker, SE (2006). "High-throughput plasmid cDNA library screening". Nature Protocols. 1 (ii): 624–32. doi:x.1038/nprot.2006.90. PMID 17406289. S2CID 205463694.
- ^ Jeremiah Organized religion (2011), conversion table
- ^ arep.med.harvard.edu A tool page with the note about the applied W-S conversion patch.
- ^ Reverse-complement tool folio with documented IUPAC lawmaking conversion, source lawmaking available.
- ^ Nomenclature Committee of the International Wedlock of Biochemistry (NC-IUB) (1984). "Classification for Incompletely Specified Bases in Nucleic Acrid Sequences". Retrieved 2008-02-04 .
- ^ Rozak DA (2006). "The practical and pedagogical advantages of an ambigraphic nucleic acid notation". Nucleosides Nucleotides Nucleic Acids. 25 (vii): 807–13. doi:10.1080/15257770600726109. PMID 16898419. S2CID 23600737.
- ^ a b Rozak, DA; Rozak, AJ (May 2008). "Simplicity, function, and legibility in an enhanced ambigraphic nucleic acrid notation". BioTechniques. 44 (6): 811–three. doi:10.2144/000112727. PMID 18476835.
External links [edit]
- Opposite complement tool
- Reverse Complement Tool @ DNA.UTAH.EDU Archived 2018-08-29 at the Wayback Machine

Write The Complementary Dna Strand,
Source: https://en.wikipedia.org/wiki/Complementarity_%28molecular_biology%29
Posted by: sheppardanstor47.blogspot.com
0 Response to "Write The Complementary Dna Strand"
Post a Comment